Modern data engineering teams face a persistent challenge of bridging the gap between sophisticated data models and the operational reality of loading data into production environments. While much attention is paid to data solution orchestration tools and workflow engines, there is a more fundamental question worth asking: What if the load control logic optimized for your environment is inside the data solution itself?
The traditional load control challenges
In a modern data platform, loading data into your warehouse or lakehouse involves a production data solution requires sophisticated control mechanisms that govern:
- What data should be loaded (e.g., only new or changed records, filtered datasets)
- When it should be loaded (e.g., scheduled intervals, event-driven triggers, dependency chains)
- How to recover from failed loads (e.g., retry logic, idempotent operations, partial failure handling)
- How to track historical loads (e.g., audit trails, load metadata, lineage tracking)
Traditionally, load control logic exists in one of two places: manually coded into bespoke scripts or abstracted into external orchestration platforms. Both approaches create friction:
- Manual scripting requires engineers to repeatedly solve the same problems across environments and SQL dialects.
- External orchestration tools introduce complexity, requiring separate tooling and configurations per platform.
- Managing dependencies between steps is a common pain point – how to ensure that objects load in the correct order often requires additional scripting or orchestration logic.
What is Native Load Control?
Native load control is managed by the target technology itself without any additional tool. It is a fundamentally different approach: embedding load control logic directly into the generated data solution code itself, tailored specifically to your target environment.
- Environment-specific generation: load control code is automatically generated in the SQL dialect or framework of your target platform (e.g., T-SQL for SQL Server, Snowflake SQL, PySpark for Databricks)
- Pipeline-level integration: control logic is embedded directly into the generated data solutions (views, and procedures) not bolted on externally
- Zero-configuration execution: data solution work out of the box with no additional scripting, wrapper code, or third-party scheduling dependencies
This approach shifts the burden of environment-specific implementation details away from manual coding or generic templates.
And while native control logic is valuable in itself, the real differentiator is that biGENIUS-X automatically generates this logic for you, saving significant time and reducing risk.
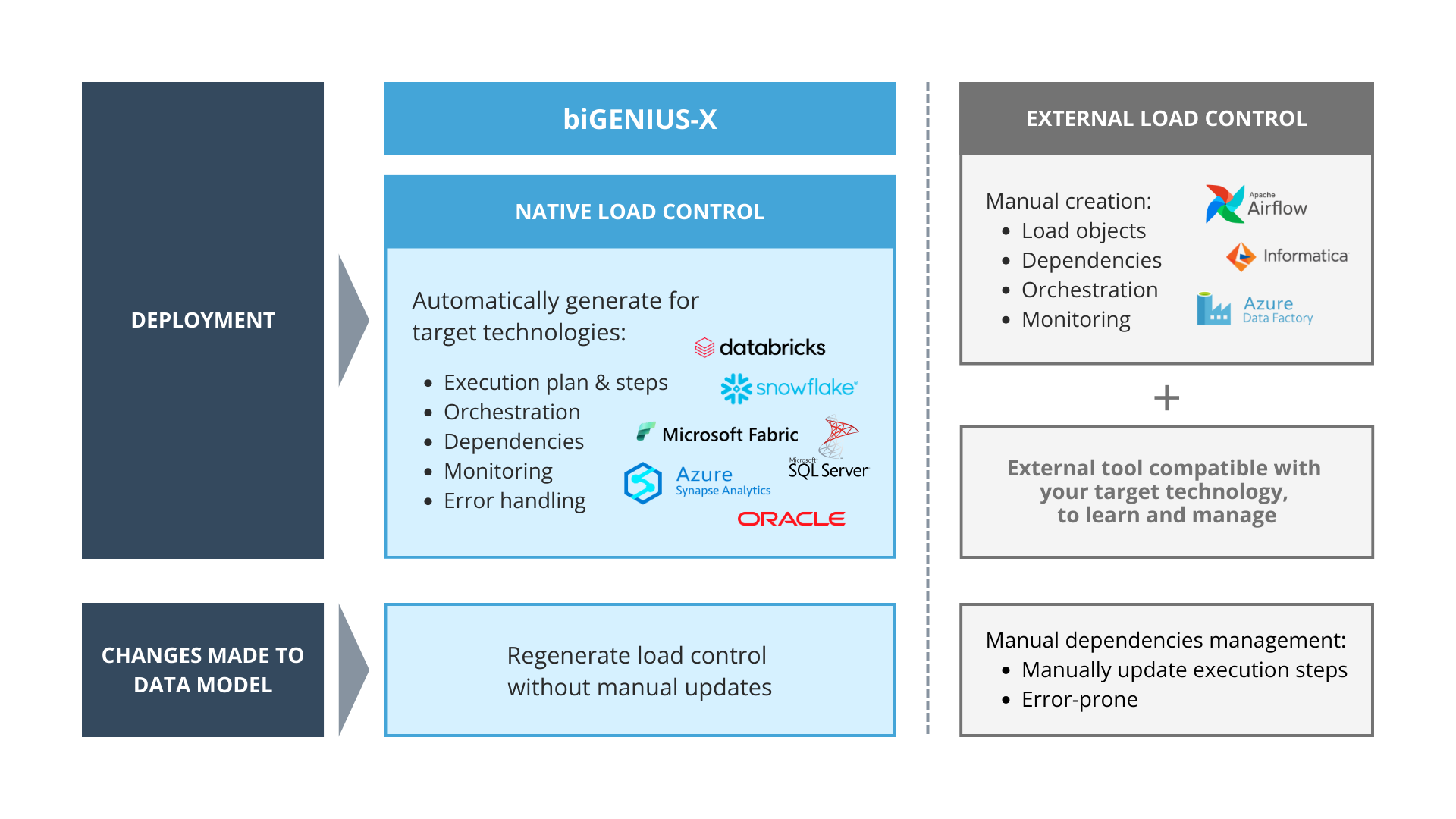
How biGENIUS-X implements Native Load Control
biGENIUS-X takes native load control from concept to practice by automatically embedding sophisticated control mechanisms into every generated data solution. When you generate a data solution, the platform includes:
1. Intelligent delta logic
Automatically detect changed or new records based on your data model's change detection strategy — whether that's timestamp-based comparisons, hash key detection, or CDC integration. This logic is generated in the native SQL dialect of your target platform.
2. Flexible load plan variants
Deploy data solutions with built-in flexibility for different operational scenarios. Need to load a single table for testing? Want to execute a full dependency chain in production? Load plan variants handle both cases without requiring code changes.
3. Comprehensive load tracking
Every execution is tracked through automatically generated metadata and runtime parameters. You get full visibility into what loaded, when it loaded, and what the results were — all stored in your environment's native format.
4. Resilient error handling
Error handling and retry logic are built directly into the SQL code itself, leveraging platform-native capabilities like transaction management, exception handling blocks, and conditional logic.
5. Dependency management via lineage
biGENIUS-X automatically generates the correct load order for your data solutions by analyzing data lineage. Dependencies are resolved and executed in the correct sequence—without requiring additional orchestration logic or manual steps.
6. Custom control plan creation
Users can define their own control plans—either across the full project or for specific segments. This adds flexibility for partial deployments, testing, or customized operational strategies.
The benefits of going native
By embedding load control natively, you gain several critical advantages:
Reduced complexity
One less tool to learn, configure, and maintain. Your data platform becomes the single source of truth for both transformation logic and load control.
Environment optimization
Generated code leverages platform-specific features (e.g., Snowflake's MERGE, Databricks' Delta Lake operations, SQL Server's stored procedures) rather than lowest-common-denominator abstractions.
Faster time-to-production
Data solutions are immediately executable after generation. No manual glue code, no orchestration configuration, no trial-and-error debugging of environment integration.
True Portability
When you need to support multiple platforms, native load control generates appropriate code for each environment rather than forcing you to maintain separate orchestration logic for each.
Conclusion
Native load control represents a shift in how we think about data solutionc deployment. Instead of treating load control as an external concern managed by orchestration layers, it becomes an intrinsic property of the data solution itself — automatically generated, environment-optimized, and immediately executable.
For data engineering teams managing complex data platforms across multiple technologies, this approach offers a path toward simpler architectures, faster deployments, and more maintainable data infrastructure.




